
There are 2 trends of Data Analysis.
Parallel DBMSs system which improves performance through parallelization of various operations, such as loading data, building indexes and evaluating queries. Vertica and Oracle 11g-r2 fall into the parallel DBMS trend.
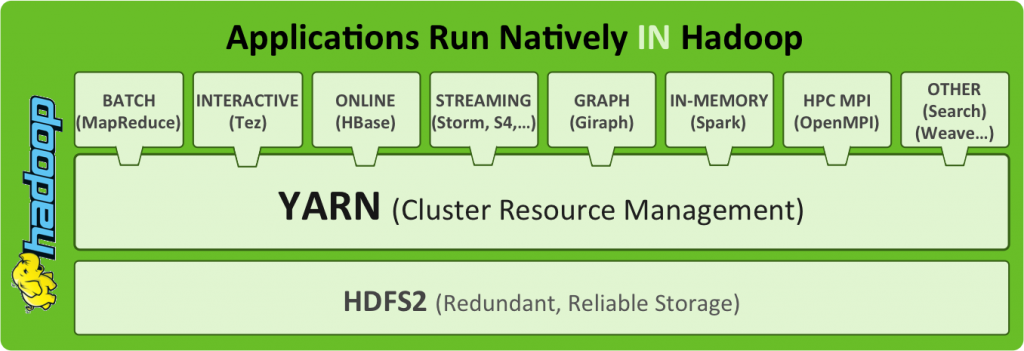
MapReduce system is a software framework that allows developers to write programs that process massive amounts of unstructured data in parallel across a distributed source of data. Hadoop with MapReduce is the other trend.
Hadoop has been touted for big data analysis but it is well suited for small data analysis as well.
We help clients choose the best tools for their data analysis and data mining requirements. If your company is small and is expected to have less than 100 nodes traditional RDBMS with Parallel processing capabilities seem to be justified.
If, however with large data of the order of 300-400 TB, MapReduce framework built on Hadoop gives best results both in terms of simplicity and cost effectiveness.
Our experience with many clients has led us to believe that with the development of load balancer and data distribution schemes Hadoop can outperform parallel DBMSs even on 100 nodes. MapReduce framework especially excels in the reduced amount of work that is lost when a hardware failure occurs compared to the parallel DBMSs.
MapReduce framework also tends to be much easier to scale and fault tolerant compared to the Parallel DBMSs. Considering the ROI, Hadoop ecosystem is being implemented at a faster rate than any other technology in the data driven enterprises. Hadoop has established itself as an enterprise-scope data management platform for multiple data types and domains. Irrespective of your use of Parallel DBMSs in your company or MapReduce framework, if you need help with your small or big data analysis, our team of experts can help and support in achieving your goal.
The Apache Hadoop framework is composed of the following modules:
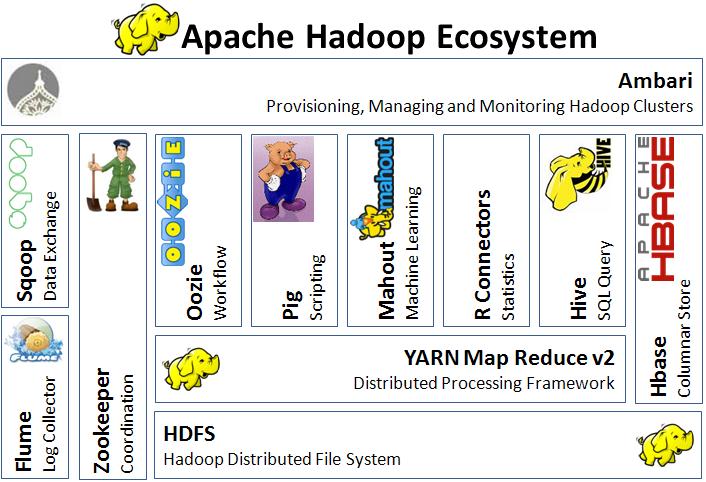
Hadoop Common – contains libraries and utilities needed by other Hadoop modules;
Hadoop Distributed File System (HDFS) – a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster;
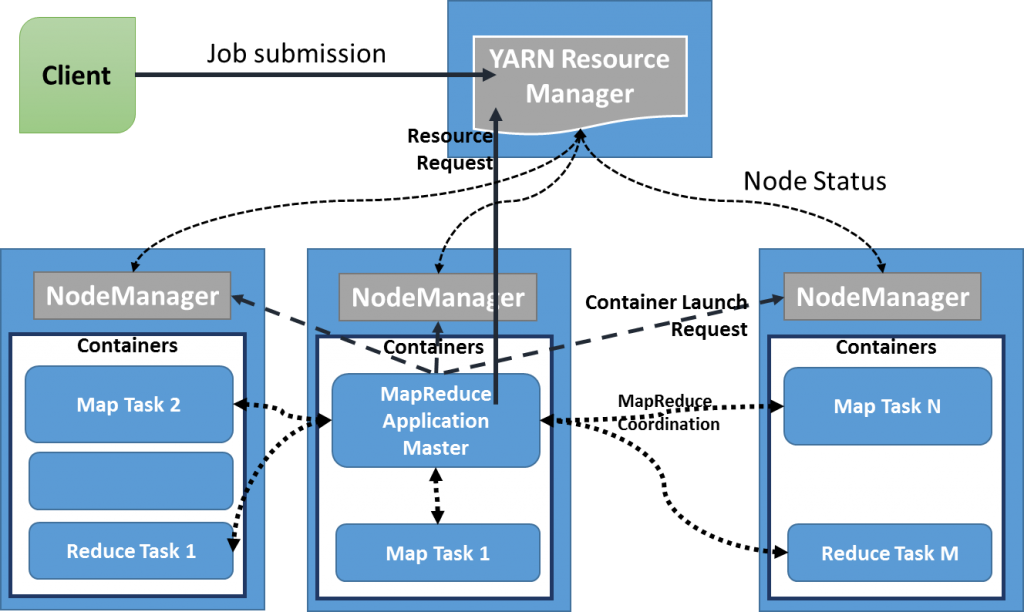
Hadoop YARN – a resource-management platform responsible for managing computing resources in clusters and using them for scheduling of users’ applications; and
Hadoop MapReduce – an implementation of the MapReduce programming model for large scale data processing.
WINSAI has trained engineers with experience in supporting Hadoop in a cloud environment.
Hadoop hosting in the cloud
Hadoop can be deployed in a traditional onsite datacenter as well as in the cloud.The cloud allows organizations to deploy Hadoop without hardware to acquire or specific setup expertise.We support Hadoop on Microsoft, Amazon, IBM,Google and Oracle.
On Microsoft Azure
Azure HDInsight is a service that deploys Hadoop on Microsoft Azure. HDInsight uses Hortonworks HDP and was jointly developed for HDI with Hortonworks. HDI allows programming extensions with .NET (in addition to Java). HDInsight also supports creation of Hadoop clusters using Linux with Ubuntu.By deploying HDInsight in the cloud, organizations can spin up the number of nodes they want and only get charged for the compute and storage that is used. Hortonworks implementations can also move data from the on-premises datacenter to the cloud for backup, development/test, and bursting scenarios.It is also possible to run Cloudera or Hortonworks Hadoop clusters on Azure Virtual Machines.
On Amazon EC2/S3 services
It is possible to run Hadoop on Amazon Elastic Compute Cloud (EC2) and Amazon Simple Storage Service (S3).As an example, The New York Times used 100 Amazon EC2 instances and a Hadoop application to process 4 TB of raw image TIFF data (stored in S3) into 11 million finished PDFs in the space of 24 hours at a computation cost of about $240 (not including bandwidth).
There is support for the S3 object store in the Apache Hadoop releases, though this is below what one expects from a traditional POSIX filesystem. Specifically, operations such as rename() and delete() on directories are not atomic, and can take time proportional to the number of entries and the amount of data in them.
Amazon Elastic MapReduce
Elastic MapReduce (EMR)was introduced by Amazon.com in April 2009. Provisioning of the Hadoop cluster, running and terminating jobs, and handling data transfer between EC2(VM) and S3(Object Storage) are automated by Elastic MapReduce. Apache Hive, which is built on top of Hadoop for providing data warehouse services, is also offered in Elastic MapReduce.
Support for using Spot Instanceswas later added in August 2011.Elastic MapReduce is fault-tolerant for slave failures,and it is recommended to only run the Task Instance Group on spot instances to take advantage of the lower cost while maintaining availability.
On CenturyLink Cloud (CLC)
CenturyLink Cloudoffers Hadoop via both a managed and un-managed model via their Hadoopoffering. CLC also offers customers several managed Cloudera Blueprints, the newest managed service in the CenturyLink Cloud big data Blueprints portfolio, which also includes Cassandra and MongoDB solutions.
Google Cloud Platform
There are multiple ways to run the Hadoop ecosystem on Google Cloud Platform ranging from self-managed to Google-managed.
Google Cloud Dataproc – a managed Spark and Hadoop service
command line tools (bdutil) – a collection of shell scripts to manually create and manage Spark and Hadoop clusters third party Hadoop distributions:-
Cloudera – using the Cloudera Director Plugin for Google Cloud Platform
Hortonworks – using bdutil support for Hortonworks HDP
MapR – using bdutil support for MapR

Contact us If you require any help on Hadoop Send us an email or call us now.